

The Two Bills of AI: Why Most PoCs Fail and How to Build Features That Sell
Most AI pilots don’t fail because the LLM models are limited. They often fail because leaders underestimate the hidden costs and the scaffolding required to make those models usable, reliable, and trusted in production scenarios. This article explores the “Two Bills of AI”: the first for what the model can do, the second for what it cannot. Paying the second bill is what separates flashy demos from features that actually sell.
At Codewalla, we start AI features the same way everyone does, with a PoC. Our LIFFT framework maps the journey from prototype to production-grade.
For our most recent AI product feature, it applies AI to cut the time our users (line managers) spend to turn fast-changing policies and manuals into training – and do it reliably and at scale. Our prototype streamlined structured output, directly integrating it into the game builder, reducing hours to minutes. But then we had to make it enterprise-grade. And for that, we had to handle prompt regression, staged rollouts, visible step-by-step UX, etc., but we did that and shipped a hot feature.
In a flat market, every new sale of that product was credited to this AI feature.
Meanwhile, industry signals appear contradictory: a widely circulated MIT study asserts that the majority of enterprise GenAI pilots yield no measurable ROI after six months, while multiple outlets have reported a "95%" success rate. At the same time, Gartner warns that a large share of “agentic AI” projects will be cancelled by 2027—primarily over cost, unclear value, and weak risk controls. Yet long-horizon analyses from McKinsey and PwC still show outsized upside if AI is built into real workflows at scale.
The reality is, first, you have to pay for what models can do. Then you have to pay for what the models cannot do.
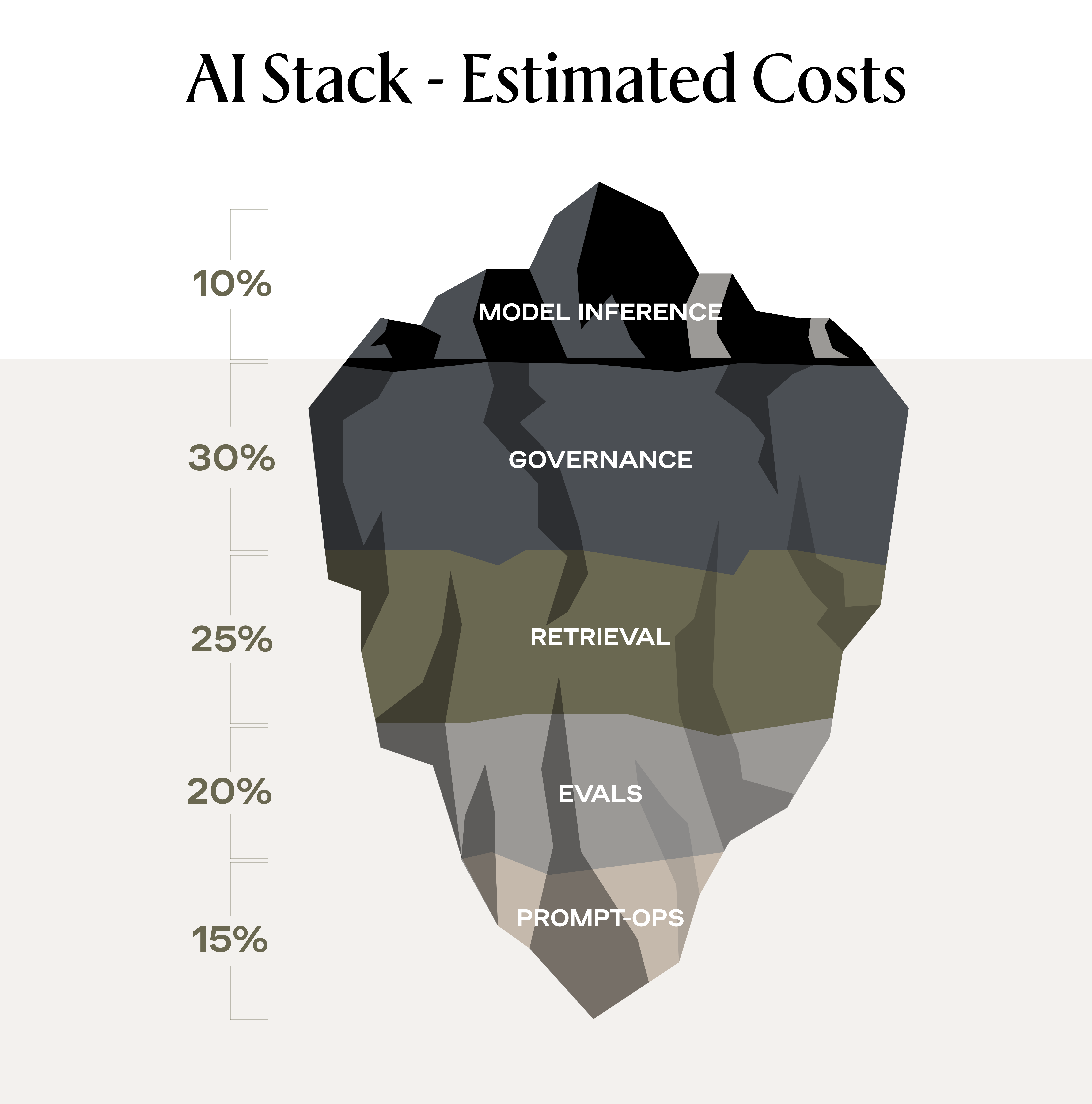
Bill One vs. Bill Two
Bill One: What the model can do
API usage, fine-tuning, prompt design—the demo-friendly portion of the work that looks predictable on a spreadsheet and impressive on stage. It’s the “Look, it works” moment, and, compared with what follows, it’s relatively cheap.
Bill Two: What the model cannot do (per-request fund)
This is the scaffolding that turns a model into a product:
- Data access that survives real life: Connectors, schema mapping, RBAC/ABAC, PII redaction, latency SLOs, and cache/RAG strategy.
- A repeatable quality harness: Golden sets, prompt regression, adversarial and refusal tests, and human-in-the-loop sign-off.
- Observability you can operate: Per-request tracing, cost telemetry, token budgets, fallback paths, and incident runbooks.
- UX that earns trust: Stepwise progress, edit/accept loops, clear boundaries, recovery paths.
- Governance that unblocks, not stalls: Policy enforcement, audit trails, vendor/model flags, and kill switches.
- Rollout discipline: Feature flags, canaries, cohort gating, staged geos, and rollback plans.
When teams underfund Bill Two, projects stall, costs escalate, and risk owners pull the brake. That’s the failure pattern Gartner is calling out in its forecast of >40% agentic AI cancellations by 2027. It’s not “AI doesn’t work”—it’s “we didn’t productise it”.
Reconciling “95% Fail” with Trillions of Upside
If near-term failure rates are so high, why do respected analysts still see trillions on the table? Because macro upside assumes you’ll operationalise AI—i.e., pay both bills—across many workflows, not just showcase a model in isolation. McKinsey estimates generative AI alone could add $2.6–$4.4T annually; PwC projects $15.7T added to global GDP by 2030. Those outcomes depend on process change and productisation, not just model capability.
Short-run “no ROI” and long-run value are not a contradiction—they’re a budgeting mismatch.
What We Saw First-Hand
Our proof of concept was up and running in the lab on day one. It became a business outcome when we paid the second invoice early:
- Quality harness to keep behavior stable while we iterated.
- Staged rollouts so we learned from behavior and avoided big-bang failures.
- Visible UX steps so managers could see and control the work rather than wonder what happened inside a black box.
That combination is why the feature was trusted—and why the sales team could sell it without caveats.
A CFO-Friendly View of Bill Two

Closing the Loop
Working with models was actually a smaller part of the problem. Building the guardrails, signals, and rollout paths is what made it a usable enterprise grade product.
For founders, that’s the real playbook: expect two bills, budget for both. That way your PoC won’t become a statistic in a study but will grow into a product that people trust and pay for.